While browsing through Scott Hanselman’s blog, I came accross a post where something called “Vertical Slice Architecture” by Jimmy Bogard is mentioned. (Anything related to software architecture easily catches my attention these days ![]() )
)
I clicked on the link and read the article…
A traditional layered/onion/clean architecture is monolithic in its approach…
The problem is this approach/architecture is… you start to get many abstractions around concepts that really shouldn’t be abstracted (Controller MUST talk to a Service that MUST use a Repository).

That diagram above is from Uncle Bob Martin’s “The Clean Architecture” blog post! Is Jimmy Bogard criticizing Clean Architecture?
Hmmmm…
I need to learn more… So I watched his talk titled “SOLID Architecture in Slices not Layers”…
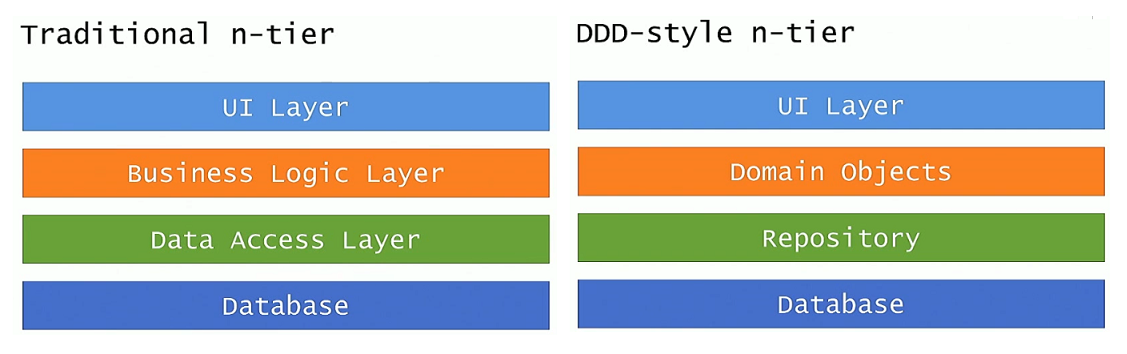
In the talk, he gave some code examples. On first look, the examples look the same as the Clean Architecture examples I found more than a year ago, except that he is directly using what Uncle Bob calls a concretion (which is Entity Framework’s DbContext) in his Interactor classes or use case handlers, such as the CreateStudentHandler below:
public class CreateStudentHandler
{
private readonly SchoolContext db;
public CreateStudentHandler(SchoolContext db)
=> this.db = db;
public void Handle(CreateStudentCommand message)
{
var student = new Student()
{
Name = message.Name,
}
this.db.Students.Add(student);
}
}
… while the Clean Architecture projects uses abstractions in their use case handlers, such as the IStudentRepository interface below:
public class CreateStudentHandler
{
private readonly IStudentRepository repository;
public CreateStudentHandler(IStudentRepository repository)
=> this.repository = repository;
public void Handle(CreateStudentCommand message)
{
var student = new Student()
{
Name = message.Name,
}
this.repository.Add(student);
}
}
public interface IStudentRepository
{
void Add(Student student);
}
public class StudentRepository : IStudentRepository
{
private readonly SchoolContext db;
public CreateStudentHandler(SchoolContext db) => this.db = db;
public void Add(Student student)
{
this.db.Students.Add(student);
}
}
Also, if he is directly using DbContext in the use case handlers then he must not have unit tests for them!
Looking at the example project on GitHub, it does not have unit tests. But it has what he calls Integration Tests.
At least it still has automated tests, right? It still deserves the attention of those who want tests in their application.
Okay… So the only difference between Vertical Slice Architecture and Clean architecture is that Vertical Slice Architecture does not use indirections (such as IStudentRepository in the code sample above) and therefore does not have unit tests(??) (Because unit testing will be hard without these indirections.)
Let’s try reading the article again…
Instead of coupling across a layer, we couple vertically along a slice. Minimize coupling between slices, and maximize coupling in a slice.
Ahhhh.. so there it is… his goal — he wants to “minimize coupling between slices, and maximize coupling in a slice.”
But we can also minimize coupling between slices, and also minimize coupling within a slice… Would that be better?
I don’t know… The answer is always “it depends” on what your goals are, I guess. ![]()
New features only add code, you’re not changing shared code and worrying about side effects. Very liberating!
Ahh! That might be the reason why Jimmy Bogard wants to maximize coupling in a slice — because he wants to minimize code sharing between slices. That sounds very good to me, because when I am new to a project and does not yet understand the codebase, I would rather see code duplication than see code reuse with lots of if/else in them. ![]()
Ultimately, I think, the difference between Clean Architecture and Vertical Slice Architecture lies on their focus or aim:
-
Clean Architecture aims to separate the business rules from the I/O (thus the indirections)
-
Vertical Slice Architecture aims to separate the code by features, aiming to minimize code sharing between features.
I think they are not necessarily mutually exclusive. I think you can combine them — Clean Vertical Slice Architecture — wherever your project and team might lead you to combine them, as long as you are aware of the tradeoffs of your chosen architecture, because, as Kent Beck says, there will always be tradeoffs…
(I cannot find a Kent Beck quote on tradeoffs, so I will just put this related quote I found ![]() )
)
One last thing… For now, I do not like using the MediatR library used in the example project (perhaps because I have not yet given much time to study how it works?). I would rather use the interfaces introduced by Steven van Deursen here and here
Steven van Deursen’s enlightening articles!
Reading more about Vertical Slice Architecture also led me to these very enlightening articles of Steven van Deursen (on the same level as the article “A Little Architecture” had enlightened me):
“This article describes how a single interface can transform the design of your application to be much cleaner, and more flexible than you ever thought possible.” — Steven van Deursen
“Two simple interfaces will change the look of your architecture… forever.” — Steven van Deursen
These two articles are kind of more elaborate explanation of what I had read from Mark Seemann on the use of decorators to implement cross-cutting concerns in his blog post “Dependency Injection is Loose Coupling” (also here)
Enjoy!
More…
Googling to understand more about this Vertical Architecture thing led me to this youtube comment thread (I think it’s good if conversations like this be not lost in the comments section of youtube, so I’m going to paste them here):
[OP]: If you’ve had to cry with the Onion Architecture, you were doing it wrong.
[C1]: We were doing onion architecture with the person that invented the term. I don’t think we could have had a better chance to get it “right”.
[OP]: Jeffrey Palermo? And there’s Robert C. Martin with Clean Architecture.
So if it failed, please enlighten me why it did?
We’re having a blast with it, ever expanding our monorepo using it. Doesn’t say it doesn’t have its drawbacks or limitations, but it’s definately better than classical architecture.
[C1]: Yes, it was about 10 years ago we started a large project with onion architecture. We had done some small projects with it, this was the first large one. About 3 months in we ripped it all out.
… But the gist was - all this layered architecture guidance presumes a value in these layers and abstractions. Things like “don’t depend directly on your ORM in case you want to swap it out”. It turns out that all these ideas and scenarios weren’t actually tested in practice, and when we actually hit these scenarios, like wanting to swap our ORM, layers and abstractions actually made things harder. So we got rid of all those layers and abstractions, and called YAGNI on it, vowing only to add those layers and abstractions in when we felt true pain. 7-8 years later, still no pain.
[OP]: @[C1] Thank you for this clean and elaborate breakdown of your experience with Onion Architecture. While I sympathise with the YAGNI argument to a certain extent, because not every abstraction is needed to enable pluggability of other implementations, that’s just a utopia, this is not the only reason for wanting to apply DI on key places (usually when you exit your system).
For us having the abstractions in place for every (let’s call it) IO device client, we were able to test all of our application’s business logic in memory with every IO device stubbed in seconds. I don’t see this being possible without DI and Onion Architecture provides a solid template to apply it in…
Also we had a requirement to deploy our applications as WAR on an old application server as well as as microservices in the cloud. There were definately cases we could get away with only writing a new implementation for the cloud, without touching our core application. This would be the Open-closed principle in SOLID.
So we’re having three layers: Core, Integration and Delivery, no more, no less. Core contains all business logic and entities, basically most code. Integration all repository logic (JPA repositories, WS/Rest clients, etc, we just call them all repositories). Delivery contains how you want to deliver the Integration (like Spring Boot, WAR, Test etc). Also there proved to be a surprising amount of reusablity in the integration layer, because the repositories are so generic, containing no business logic at all. And a good amount of flexibility, because we could wire everything up in delivery the way we want it. All in one JVM for test or as smaller deliverables in the cloud.
I wonder how all these benefits work out in vertical slices. I do have to stand by my initial point that someting must have gone wrong for this not to work. Especially for big projects it’s so suitable. Endlessly scalable. I’ve used it now for almost 6 years successfully in different size projects. Keep it clean and don’t break the architecture in a monorepo though, or there will be hell to pay.
[C2] @[C1] So did Jeffrey Palermo build this project with you, and see it fail just like you? I think you are attributing the problems to the architecture where he may have other reasons for the failure… what is his side of the story?
[C1] [C2] He disagreed with us ripping it out and applied it on a couple subsequent projects, which we ripped out again. He didn’t actually have to code against it, we did. We saw what it did to our code, and ditched it.
[C2] @[C1] yeah i get it. In my experience any application with significant complexity is going to have its issues. It’s a trade off, and I think we need to be more open about the these risks and trade offs. For example you only hear about the good stuff of event sourcing, CQRS, microservices, OOP, DRY, etc. But it’s rare to hear the issues and when NOT to use it or what details to avoid. When people have differences in opinion it is good because it highlights the bs. There are some issues with onion but it’s stuff I adapt to and often live with to avoid the alternative problems
Let me repeat the interesting statement above:
“… all this layered architecture guidance presumes a value in these layers and abstractions. Things like “don’t depend directly on your ORM in case you want to swap it out”. It turns out that all these ideas and scenarios weren’t actually tested in practice, and when we actually hit these scenarios, like wanting to swap our ORM, layers and abstractions actually made things *harder*.”
Hmmmm…
Reading “A Little Architecture” of Uncle Bob Martin and other resources on Clean Architecture was kind of an enlighnement to me because it seemed to have with it attached the promise of control with our software projects.
But reading that experience from the comments thread makes me rethink about using Clean Architecture in all of my future software projects ![]()
A big plus for this Vertical Slice Architecture is that it seems to help new programmers quickly understand how the components of a project communicate, as hinted in another youtube comment:
César Afonso: As a team leader who had to deal with many many trainees entering one projects without knowledge on architectures or even programing, and leaving after a few months, I started to use a similar architecture sometime in 2015 on my projects.
On my experience, it makes a project look uglier to expert developers, because the separation of layers is not pretty well defined…
But on the other [hand], … it’s easier to new delevopers [to] understand the project and the components… they are not so afraid of changing something… the projects have less bugs and are easier to find and fix it.
… The indirections in projects employing the Clean Architecture will confuse programmers who do not yet understand the Dependency Inversion Principle. ![]() I think making beginning programmers understand the mindset behind Vertical Slice Architecture will help them stucture their code well even when they do not yet know much about architecture — “for now, it’s okay to have duplicates in code, as long as there is very clear separation between features; we can refactor things later on when we already know how to refactor them”.
I think making beginning programmers understand the mindset behind Vertical Slice Architecture will help them stucture their code well even when they do not yet know much about architecture — “for now, it’s okay to have duplicates in code, as long as there is very clear separation between features; we can refactor things later on when we already know how to refactor them”.
(Update: May 23, 2019)
While googling for “vertical architecture in angularjs”, I came across a series of blog posts, OJ Raqueño, which will give you ideas on why you should use Vertical Slice Architecture in your projects:
-
The Tyranny of Horizontal Architectures (and How You Might Escape): Part 1
-
The Tyranny of Horizontal Architectures (and How You Might Escape): Part 2
You might also be interested in these (from the same author):
